
Brainly GraphQL development evolution

Beginnings
Engineers at Brainly have been early adopters of GraphQL in 2016. GraphQL was started to create a common API gateway for the growing amount of distributed services. Back when we started the only sensible implementation was the reference node.js GraphQL server from Facebook, the tooling was mostly unavailable and our knowledge on how to efficiently work within this environment was not there yet.
Fast-forward a couple months and we’re in 2017. There are roughly 6 services integrated into the API and 8 backend developers.
Each service integration is handwritten and follows the same structure:


- Builder is responsible for validating the data received from the service and transforming it into the entity.
- Entity resembles the data retrieved from the service. The entity is a class with all fields set via the constructor.
- Endpoint is another JS class and is responsible for building the endpoint address to call. It receives the base URL and other data needed for creating the path.
- HTTP combines all of the above to make the request, handle any HTTP errors and process data.
- It uses a
fetchinstance that is decorated with multiple functionalities, i.e. default timeouts or tracing - It’s worth noting that it was also responsible for suppressing any 404 into null or an empty array.
- It uses a
- Errors file contains package-specific errors that could be thrown while processing requests.
- Provider is required for all packages and has a register method that takes the container, builds all necessary dependencies and returns a combined object to the server init.
For some cases this structure could also be extended with a resolver directory that provided a resolver-like function that would be called from the root resolver while resolving specific fields.
The amount of files required to integrate a single service has usually exceeded 10. There was also some toll to wire everything into the resolving chain. The complexity was sometimes so high that Flow did not always know how to resolve types, therefore not catching type errors.
Changing the status quo
In 2018 we have started the ongoing process of modernising the stack to improve development velocity and splitting ownership of code while ensuring that we keep best in class reliability of the service and catch any mistakes early on.
We’ve migrated to Apollo Server which allowed us to introduce the concept of data sources. The DataSource is an abstract concept of fetching data from different sources for resolvers in GraphQL. Since our GraphQL acts as an API gateway for other HTTP services this is a match made in heaven.
Apollo’s RESTDataSource provides many important functionalities:
- Memoisation of requests – helpful when calling GET on exactly the same route from different resolvers – the caller receives the same Promise and no external call is necessary
- Caching of responses – if the service sends caching headers the data source will understand them and store in a cache defined by us. This allows us to off-load calling external services at all when we have previously received a cacheable response.
- Abstracting HTTP methods to a simple interface – it’s enough to use “this.post” to spin proper requests and unmarshall data depending on the content type.
Automate all the things
With that ready, we started to work on automating. The first thing we did was hooking a generator that takes all registered Swagger schemas and generated Flow types for all object definitions in the schema.
The new structure, stil grouped by the service was:

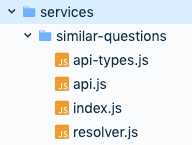
- API types is the result of type generation from Swagger
- API is the place for a class extending RESTDataSource. The class implements functions for each path we want to call and uses the generated types to inform Flow what is being returned.
- Resolver implements all resolvers that are resolving data connected to the service in this directory
- Index exports API and resolvers in a traditional JS manner
Next thing was to leverage what tooling has emerged over the time when it comes to using GraphQL schema. We have hooked GraphQL Code Generator to generate Flow types for all objects in the schema as well as for resolvers. Thanks to that we were able to ensure that every resolver returns correct data as well as it’s doing its job based on the correct context of parent and arguments.
With those ready we have continued to integrate new services with less code and more success. But we wouldn’t stop there. We saw opportunities to improve:
Generating resolver stubs from GraphQL schema
Since we already have tools for introspecting schema at hand, we wanted to use them to provide scaffolding for resolvers. The obvious obstacle was – where should generated resolvers land? After many discussions we have finally agreed that we’d want our resolvers to resemble their relationship to the schema and not be coupled to any of the services. This is important because some resolvers use more than one service to fulfil the request.
The result is the structure:
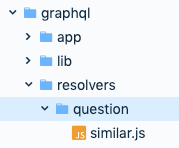

Where the directory resembles a GraphQL type and file contains a resolver for a field of the same name that is resolved on that type. The image above a similar field resolver on the type Question. It’s this simple.
With this ready, we have leveraged Yeoman to provide an interactive generation of resolver stub with a simple run of yarn generate-resolver:

async function similar(
parent: gql.Question,
args: {},
{dataSources: {similarQuestions}}: Context
): Promise<Array<gql.SimilarQuestion>> {
// resolve code
}
export default {
Question: ({
similar,
}: $Exact<gql.QuestionResolvers<Context, gql.Question>>),
};Generating entire Data Source from Swagger
Since we already use Swagger schemas to generate Flow data types, why not generate the entire data source? There’s still no tool that would automate that for us since all generators require too much effort to adjust. Because of that we went ahead and wrote our own datasource generator.


Every generated data source has its own workspace package and contains the extension of RESTDataSource that is in the datasource workspace package and Flow data types.
New quality in integrating services
After all that work we have come to a process that automated most of work required for new integrations and is now as follows:
- Introduce a change to GraphQL schema
- Generate Flow types from GraphQL schema
- Generate a data source from Swagger schema
- Generate a resolver stub for new fields in schema
- Write resolver logic
- Write tests
- Ship it.
The future
Further generation of code
While we already have achieved some big improvements to the ratio of code written vs. generated, we still see many opportunities to extend that.
One of possibilities we are looking at is how to scaffold handlers in the mocked-api. The mocked-api is our helper service that serves mock data during integration tests of GraphQL. This would help with reducing manual work to simply defining desired responses for each endpoint available in the service’s Swagger schema.
Another thing we’d like to tackle is automatically wiring the data source to the server so that once it’s generated, it will be ready to use within your resolvers.
Federation
We are closely looking at possible applications of the Apollo Federation. If used, we could transform our current setup into smaller GraphQL servers managed entirely by teams owning a given business domain. This would allow the team to use the stack of their choice as well as develop and deploy their service independently of the main gateway.
While this would improve some aspects, we know that this might mean that we would be adding another hop to serving the request. The solution to this would be implementing a federated GraphQL server directly in your service and skipping traditional HTTP API altogether. Unfortunately, this is not yet possible due to the fact that all our other services are not written in Node.js and their respective language-specific Federation support might not be there yet.
Ownership
With the generation of most parts of the code, we would like to move ownership of all possible files to teams owning the integration while reserving ownership of core components to current GraphQL maintainers. We have already started the process by splitting schema files and we are considering ways to automate setting ownership for newly generated files.
Clients involvement
Currently the engineers introducing changes to GraphQL are mostly backend engineers. Since GraphQL is client-driven by definition, we are considering the possible ways on if and how to involve our actual clients into designing or even implementing integrations with backend services.

")
